From Human Videos to Robot Manipulation: A Survey on Scalable Vision-Language-Action Learning with Human-centric Data
Abstract
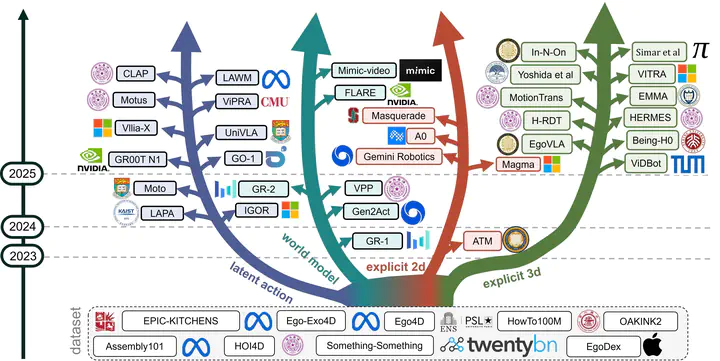
Recent progress in generalizable embodied control has been driven by large-scale pretraining of Vision–Language–Action (VLA) models. However, most existing approaches rely on large collections of robot demonstrations, which are costly to obtain and tightly coupled to specific embodiments. Human videos, by contrast, are abundant and capture rich interactions, providing diverse semantic and physical cues for real-world manipulation. Yet, embodiment differences and the frequent absence of task-aligned annotations make their direct use in VLA models challenging. This survey provides a unified view of how human videos are transformed into effective knowledge for VLA models. We categorize existing approaches into four classes based on the action-related information they derive, (i) latent action representations that encode inter-frame changes, (ii) predictive world models that forecast future frames, (iii) explicit 2D supervision that extracts image-plane cues and (iv) explicit 3D reconstruction that recovers geometry or motion. Beyond this taxonomy, we highlight three key open challenges in this area, structuring unstructured videos into trainingready episodes, grounding video-derived supervision into robot-executable actions under embodiment and viewpoint heterogeneity, and designing evaluation protocols that better predict realworld deployment performance and transfer efficiency, thereby informing future research directions.