Abstract
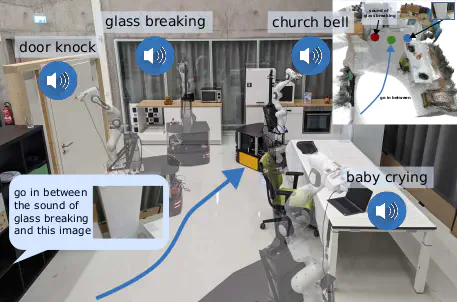
While interacting in the world is a multi-sensory experience, many robots continue to predominantly rely on visual perception to map and navigate in their environments. In this work, we propose Audio-Visual-Language Maps (AVLMaps), a unified 3D spatial map representation for storing cross-modal information from audio, visual, and language cues. AVLMaps integrate the open-vocabulary capabilities of multimodal foundation models pre-trained on Internet-scale data by fusing their features into a centralized 3D voxel grid. In the context of navigation, we show that AVLMaps enable robot systems to index goals in the map based on multimodal queries, e.g., textual descriptions, images, or audio snippets of landmarks. In particular, the addition of audio information enables robots to more reliably disambiguate goal locations. Extensive experiments in simulation show that AVLMaps enable zero-shot multimodal goal navigation from multimodal prompts and provide 50% better recall in ambiguous scenarios. These capabilities extend to mobile robots in the real world – navigating to landmarks referring to visual, audio, and spatial concepts. Videos and code are available at https://avlmaps.github.io/.