Oier Mees
Oier Mees
Home
Latest
Publications
Experience
Contact
Light
Dark
Automatic
1
From Human Videos to Robot Manipulation: A Survey on Scalable Vision-Language-Action Learning with Human-centric Data
IJCAI 2026
Zhiyuan Feng
,
Qixiu Li
,
Huizhi Liang
,
Rushuai Yang
,
Yichao Shen
,
Zhiying Du
,
Zhaowei Zhang
,
Yu Deng
,
Li Zhao
,
Hao Zhao
,
Zongqing Lu
,
Oier Mees
,
Marc Pollefeys
,
Jiaolong Yang
,
Baining Guo
PDF
Cite
Project
mimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
RSS 2026
Jonas Pai
,
Liam Achenbach
,
Victoriano Montesinos
,
Benedek Forrai
,
Oier Mees
,
Elvis Nava
PDF
Cite
Code
Project
Training Strategies for Efficient Embodied Reasoning
CoRL 2025
William Chen
,
Suneel Belkhale
,
Suvir Mirchandani
,
Danny Driess
,
Oier Mees
,
Karl Pertsch
,
Sergey Levine
PDF
Cite
Project
FAST: Efficient Action Tokenization for Vision-Language-Action Models
RSS 2025
Karl Pertsch
,
Kyle Stachowicz
,
Brian Ichter
,
Danny Driess
,
Suraj Nair
,
Quan Vuong
,
Oier Mees
,
Chelsea Finn
,
Sergey Levine
PDF
Cite
Code
Project
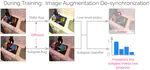
Beyond Sight: Finetuning Generalist Robot Policies with Heterogeneous Sensors via Language Grounding
ICRA 2025
Joshua Jones
,
Oier Mees
,
Carmelo Sferrazza
,
Kyle Stachowicz
,
Pieter Abbeel
,
Sergey Levine
PDF
Cite
Code
Dataset
Project
GHIL-Glue: Hierarchical Control with Filtered Subgoal Images
ICRA 2025
Kyle B Hatch
,
Ashwin Balakrishna
,
Oier Mees
,
Suraj Nair
,
Seohong Park
,
Blake Wulfe
,
Masha Itkina
,
Benjamin Eysenbach
,
Sergey Levine
,
Thomas Kollar
,
Benjamin Burchfiel
PDF
Cite
Code
Project
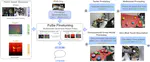
Scaling Robot Policy Learning via Zero-Shot Labeling with Foundation Models
CoRL 2024
Nils Blank
,
Moritz Reuss
,
Marcel Rühle
,
Ömer Erdinç Yağmurlu
,
Fabian Wenzel
,
Oier Mees
,
Rudolf Lioutikov
PDF
Cite
Project
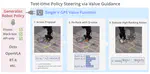
Steering Your Generalists: Improving Robotic Foundation Models via Value Guidance
CoRL 2024
Mitsuhiko Nakamoto
,
Oier Mees
,
Aviral Kumar
,
Sergey Levine
PDF
Cite
Project
The Ingredients for Robotic Diffusion Transformers
ICRA 2025
Sudeep Dasari
,
Oier Mees
,
Sebastian Zhao
,
Mohan Kumar Srirama
,
Sergey Levine
PDF
Cite
Code
Dataset
Project
LeLaN: Learning A Language-conditioned Navigation Policy from In-the-Wild Videos
CoRL 2024
Noriaki Hirose
,
Catherine Glossop
,
Ajay Sridhar
,
Dhruv Shah
,
Oier Mees
,
Sergey Levine
PDF
Cite
Code
Project
»
Cite
×